ROADtools - 微软云上域渗透框架
前言
目前,越来越多的企业选择将企业的域环境部署到云服务器中,虽然关于Windows的活动目录架构研究越来越多,但是云上域的相关介绍却少之又少,Dirk-jan Mollema通过对Azure AD的深入研究,结合自己开发诸多工具的经验,编写了ROADtools。
ROADtools - 微软Azure AD渗透框架
在过去的一年半中,我对Azure AD及其工作方式进行了大量的摸索。 Azure AD在企业中越来越普遍,因此安全性也变得越来越重要。尽管传统的Windows Server Active Directory已经拥有大量的研究和工具,但我认为Azure AD在这方面是落后的。在本文中,我将介绍ROADtools框架中的第一个工具:ROADrecon。该框架是在我研究期间开发的,希望对任何想要分析Azure AD的人(无论是从红队还是从蓝队的角度)都有所启发。这篇文章是该系列文章的第一部分,在该系列文章中,我将深入介绍Azure AD和ROADtools框架。 ROADtools和ROADrecon都是免费的开源工具,可以在我的GitHub上找到。我还直播编写了此处的大多数内容,您可以在油管上观看。
为什么使用这个框架
每当我发现自己在探索新网络或研究新主题时,我都想通过一种易于理解的方式去了解尽可能多的信息。在Active Directory环境中,使用LDAP来查询信息相对简单,并且有许多工具可以查询此信息并将其转换为更易于使用的格式。我之前编写了一个简单的工具ldapdomaindump,试图保存所有可以离线收集的信息,以便我能快速知道“该用户还属于哪一个组”或“他们是否有对系统X有价值的组”?
后来,很多公司经常使用Microsoft Office 365并将其产品迁移到Azure,实际Azure上并没有一个工具可以让人快速了解其环境。 Azure Portal需要通过多次点击才能找到需要内容,并且可以禁用除管理员以外的任何用户。各种Powershell模块、.NET库和其他查询Azure AD的官方方法对它们提供的信息、身份验证方法和适用于它们的限制都提供了不同程度的支持。当研究Azure AD时,我希望有一种方法,可以使用任何身份验证方法(无论是否合法获得)来访问所有可能的信息,并且可以离线使用。由于没有一种官方方法可以提供这种可能性,我很快意识到构建自定义框架是实现它的唯一方法。因此,我为自己设定了一些目标:
- 为红队和蓝队提供工具,以一种便捷的方式浏览所有Azure AD数据。
- 从互联网端显示可用的丰富信息,他可以是拥有一套有效凭证的任何人。
- 更好地了解Azure AD的工作原理和可能性。
- 提供一个框架,人们可以在该框架上建立并扩展其用例。
从编写ldapdomaindump的过程中,我确实学到了一些东西,它将所有信息保留在内存中,直到计算出所有递归组成员关系为止,然后将其写入磁盘。正如预期的那样,在其中有数千个用户的环境中,这种实用性相当糟糕。我花了很多时间思考如何做(还编写了更多的实际代码),而忽略了所有访问Azure AD的方式,所以今天是 Rogue Office 365 and Azure (active) Directory tools的第一个版本!
ROADrecon
这个框架中的第一个(可能也是最常用的)工具是ROADrecon。简而言之,它是这样做的:
- 使用自动生成的元数据模型在磁盘上创建SQLAlchemy支持的数据库。
- 使用Python中的异步HTTP调用将Azure AD图中的所有可用信息转储到此数据库。
- 提供插件来查询这个数据库并且输出它到一个有用的格式。
- 在Angular中提供一个广泛的接口,可以直接查询离线数据库进行分析。
从哪里获取数据
因为Azure AD是一种云服务,所以没有办法逆向它是如何工作的,也没有一个中央存储库来存储你可以访问的所有数据。因为Azure AD与Windows Server AD完全不同,所以也没有LDAP来查询目录。在研究Azure并查看Azure Portal中的请求时,我注意到Azure Portal在调用Azure AD图的另一个版本,即1.61-internal版本。
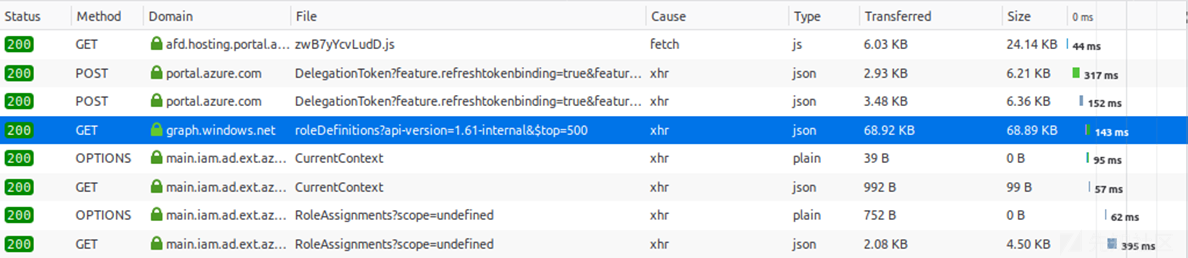
Azure AD图的内部版本比微软提供的任何官方API都要公开更多的数据。我谈到了一些有趣的东西,你可以在我的BlueHat Seattle talk里发现这个API。虽然人们可能不应该使用这个版本,但它仍然对任何用户都是可用的。默认情况下,即使当Azure Portal受到限制,也可以以一个通过身份验证的用户身份查询有关该目录的几乎所有信息。
下一个问题是如何以结构化的方式在本地存储这些数据。API将所有内容以JSON对象的形式进行流处理,这种格式对于传输数据很有用,但当存储和搜索数据却不是这样。所以理想情况下,我们应该有一个数据库,其中对象及其关系被自动存储和映射。为此,ROADrecon使用SQLAlchemy对象关系映射器(ORM)。这意味着,ROADrecon定义对象的结构及其关系,SQLAlchemy决定如何从底层数据库存储和检索这些对象。为了创建对象结构,ROADrecon使用Azure AD图公开的OData元数据定义。这个XML文档定义了目录中的所有对象类型、以及它们的属性和关系。
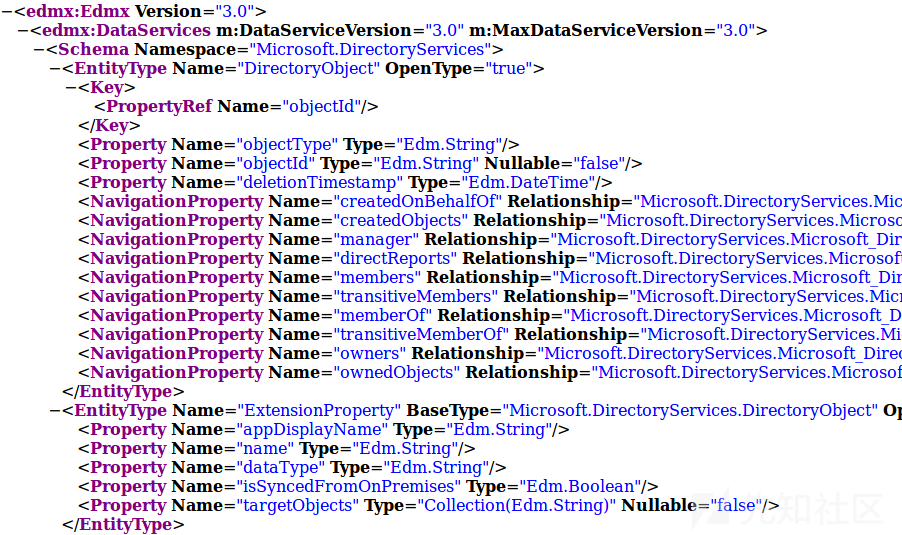
我写了一些相当简陋的代码,将大部分元数据XML自动转换为整洁和定义良好的数据库结构,如下所示:
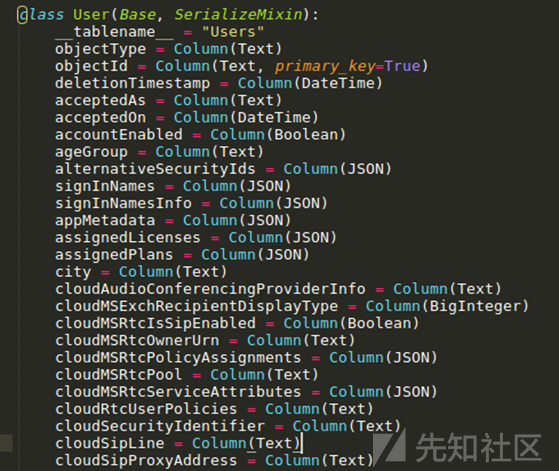
然后SQLAlchemy为这个模型创建数据库,默认情况下是一个SQLite数据库,但是也支持PostgreSQL(在我的测试中,性能差异很小,但是SQLite看起来稍微快一些)。这样做的主要优点是事后查询数据非常容易,而不需要自己编写任何SQL查询。
这个数据库模型实际上不是ROADrecon的一部分,而是roadlib ROADtools的中央库组件。这样做的原因是,如果你想构建一个外部工具,与ROADrecon填充的数据库接口交互,你实际上不需要自己导入ROADrecon及其所有依赖。相反,您可以导入包含数据库逻辑的库,它不依赖于ROADrecon用于转换和显示数据的所有第三方代码。
导出数据
在Azure AD中,ROADrecon使用3个步骤来转储和探索数据:
- 认证 - 使用用户名/密码、访问令牌、设备代码流等
- 将数据转储到磁盘
- 浏览数据或使用插件将其转换为有用的格式
认证
身份验证是开始收集数据的第一步。ROADrecon提供了相当多的认证选项:
usage: roadrecon auth [-h] [-u USERNAME] [-p PASSWORD] [-t TENANT] [-c CLIENT] [--as-app] [--device-code] [--access-token ACCESS_TOKEN]
[--refresh-token REFRESH_TOKEN] [-f TOKENFILE] [--tokens-stdout]
optional arguments:
-h --help show this help message and exit
-u USERNAME --username USERNAME
Username for authentication
-p PASSWORD --password PASSWORD
Password (leave empty to prompt)
-t TENANT --tenant TENANT
Tenant ID to auth to (leave blank for default tenant for account)
-c CLIENT --client CLIENT
Client ID to use when authenticating. (Must be a public client from Microsoft with user_impersonation permissions!).
Default: Azure AD PowerShell module App ID
--as-app Authenticate as App (requires password and client ID set)
--device-code Authenticate using a device code
--access-token ACCESS_TOKEN
Access token (JWT)
--refresh-token REFRESH_TOKEN
Refresh token (JWT)
-f TOKENFILE --tokenfile TOKENFILE
File to store the credentials (default: .roadtools_auth)
--tokens-stdout Do not store tokens on disk pipe to stdout instead最常见的可能是用户名+密码身份验证或设备代码身份验证。用户名+密码是最简单的,它不支持任何方式的MFA,因为它是非交互的。如果您的帐户需要MFA,您可以使用设备代码流,它将为您提供在浏览器中输入的代码。这里有更多的选项,在大多数情况下不需要使用,但用于高级选项时使用,或者如果您想使用通过不同方法获得的令牌。我计划将来写一篇关于Azure AD认证和红队可用选项的博客。默认情况下,ROADrecon将假装是Azure AD PowerShell模块,因此将继承其访问Azure AD图内部版本的权限。默认情况下,ROADrecon将把获得的身份验证令牌存储在磁盘上一个名为' .roadtools_auth '的文件中。根据身份验证方法的不同,此文件包含长时间的刷新令牌,可以保持您一直处于登录状态。这个文件还与使用roadlib作为身份验证库的任何(将来的)工具兼容。如果不想在磁盘上存储令牌,还可以将它们输出到stdout,这样就可以直接将它们导入下一个命令。
收集所有数据
第二步是数据收集,这是由“roadrecon gather”命令完成的。这有几个简单的选择:
usage: roadrecon gather [-h] [-d DATABASE] [-f TOKENFILE] [--tokens-stdin] [--mfa]
optional arguments:
-h --help show this help message and exit
-d DATABASE --data DATABASE
Data file. Can be the local data name for SQLite or an SQLAlchemy compatible URL such as
postgresql+psycopg2://dirkjan@/roadtools. Default: roadrecon.db
-f TOKENFILE --tokenfile TOKENFILE
File to read credentials from obtained by roadrecon auth
--tokens-stdin Read tokens from stdin instead of from disk
--mfa Dump MFA details (requires use of a privileged account)默认情况下,它将把它转储到当前目录中名为roadrecon.db的SQLite数据库中。使用postgresql需要一些额外的设置和psycopg2的安装。令牌的选项取决于您在身份验证阶段使用的设置,如果不用更改,则不需要这些设置。目前唯一的另外一个选择是,是否希望在多因素身份验证上转储数据,比如每个用户设置了哪些方法。这是数据收集的唯一特权组件,它需要一个具有角色成员资格的帐户,以便访问该信息(例如全局管理员或身份认证管理员)。
ROADrecon将分两个阶段请求所有可用的数据。第一阶段使用Python库aiohttp并行请求所有用户、组、设备、角色、应用程序和服务主体。请求这些对象是并行完成的,Azure AD图返回100个条目,其中还包含一个用于请求下一个页面的令牌。这意味着请求接下来的100个条目只能在返回前100个条目的结果之后执行,这实际上仍然是一个串行过程。每个对象类型都是并行请求的,但是在继续之前,它仍然需要等待最慢的并行作业完成。
在第二阶段,查询所有关系,例如组成员关系、应用程序角色、目录角色成员和应用程序/设备所有者。因为这是每个单独的组执行的,所以这里会有更多的并行任务,因此使用aiohttp库的速度收益会变得更大。为了限制内存中对象的数量,ROADrecon定期将数据库的更改写入到磁盘(大约1000个更改或新条目块)。这不是异步完成的,因为在我的测试中,性能瓶颈似乎是HTTP请求而不是数据库的读写。
总的来说,整个过程是相当快的,肯定比在我重写到异步代码之前以串行方式转储所有东西要快得多。导出一个有5000个用户的Azure AD环境大约需要100秒。对于我测试过的真正大的环境(大约12万用户),这仍然会花费相当长的时间(大约2小时),因为在数据收集的第一阶段需要串行请求的对象数量实在太多。
(ROADtools) user@localhost:~/ROADtools$ roadrecon gather --mfa
Starting data gathering phase 1 of 2 (collecting s)
Starting data gathering phase 2 of 2 (collecting properties and relationships)
ROADrecon gather executed in 7.11 seconds and issued 490 HTTP requests.使用ROADrecon GUI探索数据
现在我们可以访问数据库中本地磁盘上的所有数据,我们可以开始研究它,并将其转换为便于理解的格式。它有多种选择,ROADrecon在构建时考虑到了可扩展性,因此它有一个基本的插件框架,允许编写插件来获取数据库中的数据并将其输出到一些有用的东西中。对于真正简单的用例,您甚至不需要ROADrecon,通过编写几行代码就可以完成您想要它做的事情。下面是一个简单的工具示例,只需要您从roadlib导入数据库定义,然后打印数据库中所有用户的名称:
from roadtools.roadlib.def.data import User
import roadtools.roadlib.def.data as data
session = data.get_session(data.init())
for user in session.query(User):
print(user.displayName)大多数情况下你不需要编写任何代码,因为ROADrecon已经提供了一些导出插件和功能齐全的GUI。当运行roadrecono -gui或roadrecon gui命令时,它会通过Flask启动一个本地web服务器,该服务器会公开一个REST API,这个API可以被这个单页Angular JavaScript应用程序访问。
目前功能:
- 用户/设备/组列表
- 单页目录角色概述
- 应用程序概述
- 服务主体详情
- 角色/ OAuth2权限分配
- MFA概述
以下是一些屏幕截图(或观看demo):
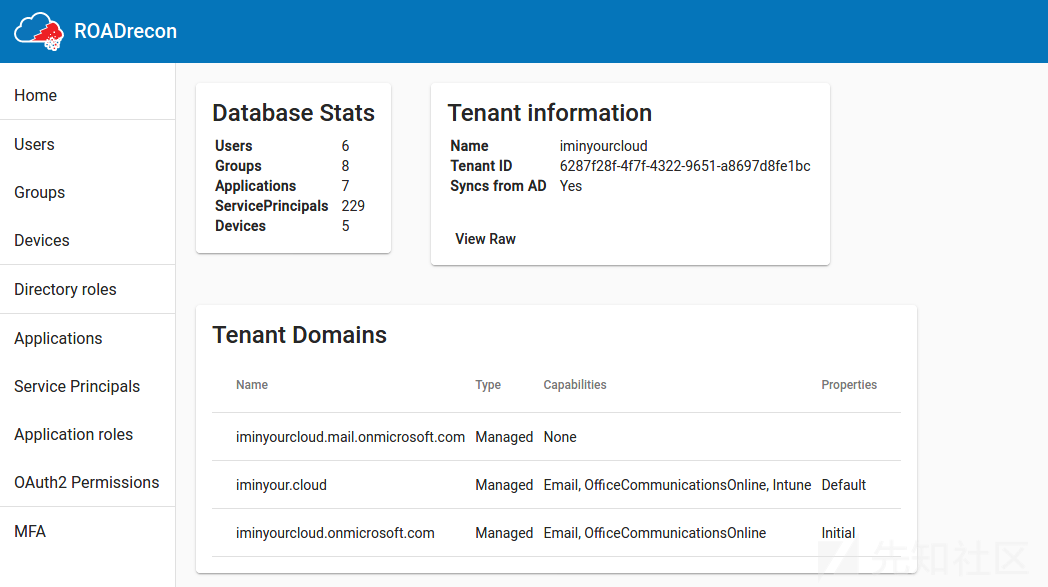
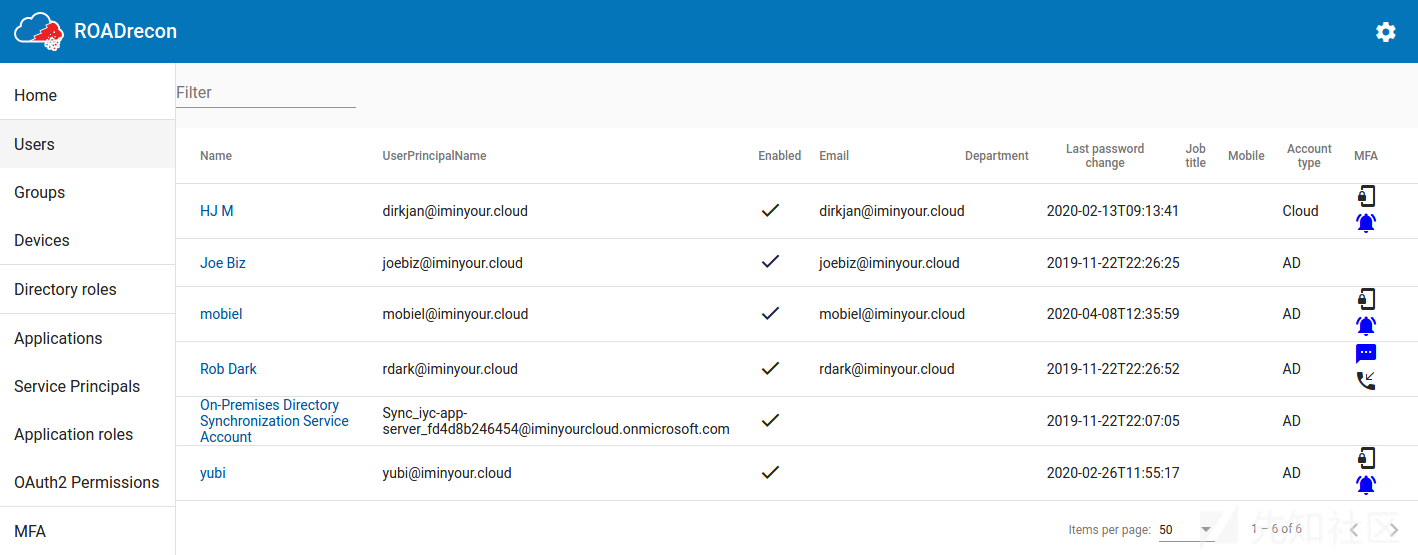
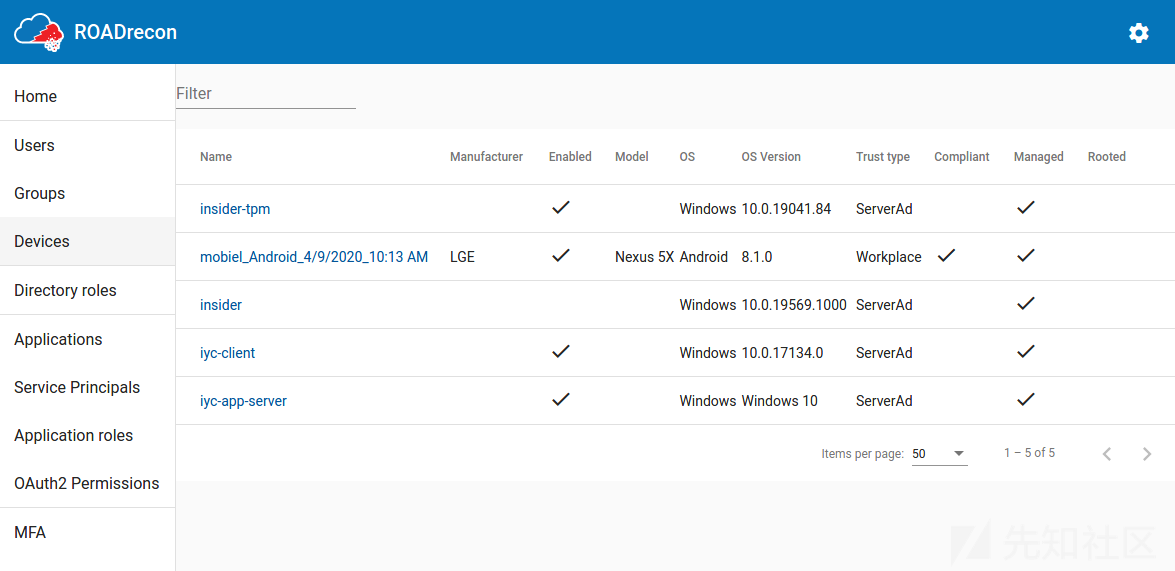
这些清单的一个常见组成部分是,最重要的属性显示在表中,表支持分页和快速筛选选项。如果您想知道一个对象的更多细节,或者它是如何与其他组件关联的,那么可以单击大多数对象。当单击时,更详细的信息将显示在弹出窗口中。
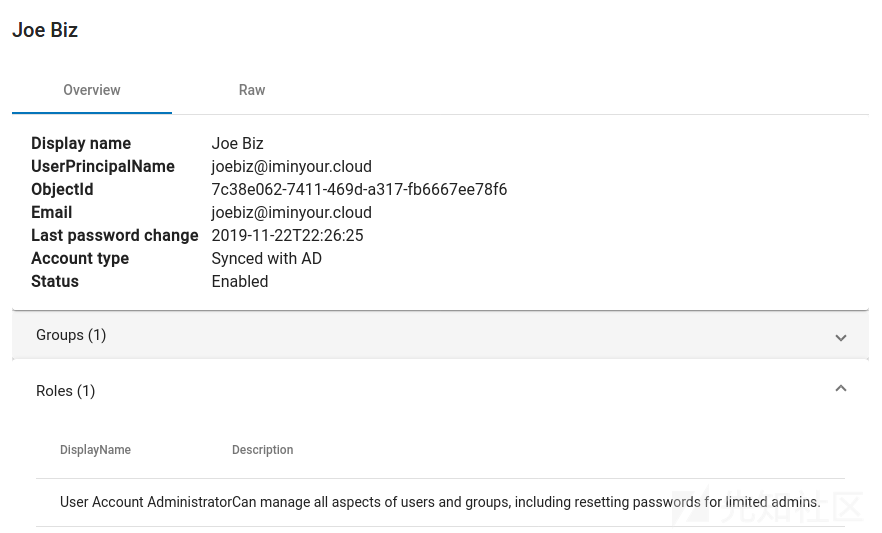
每个对象都有一个“raw”视图,它以可折叠的JSON结构显示所有可用的属性(这些属性直接来自Azure AD内部API)。
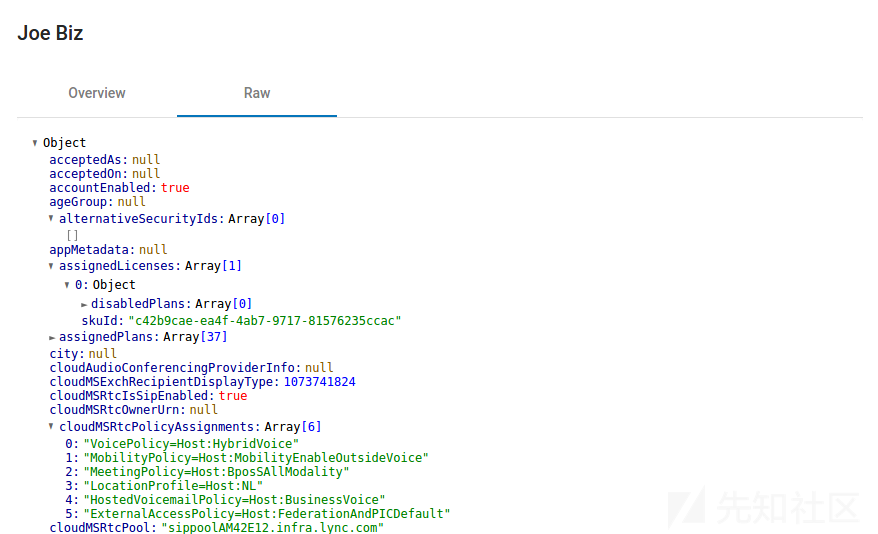
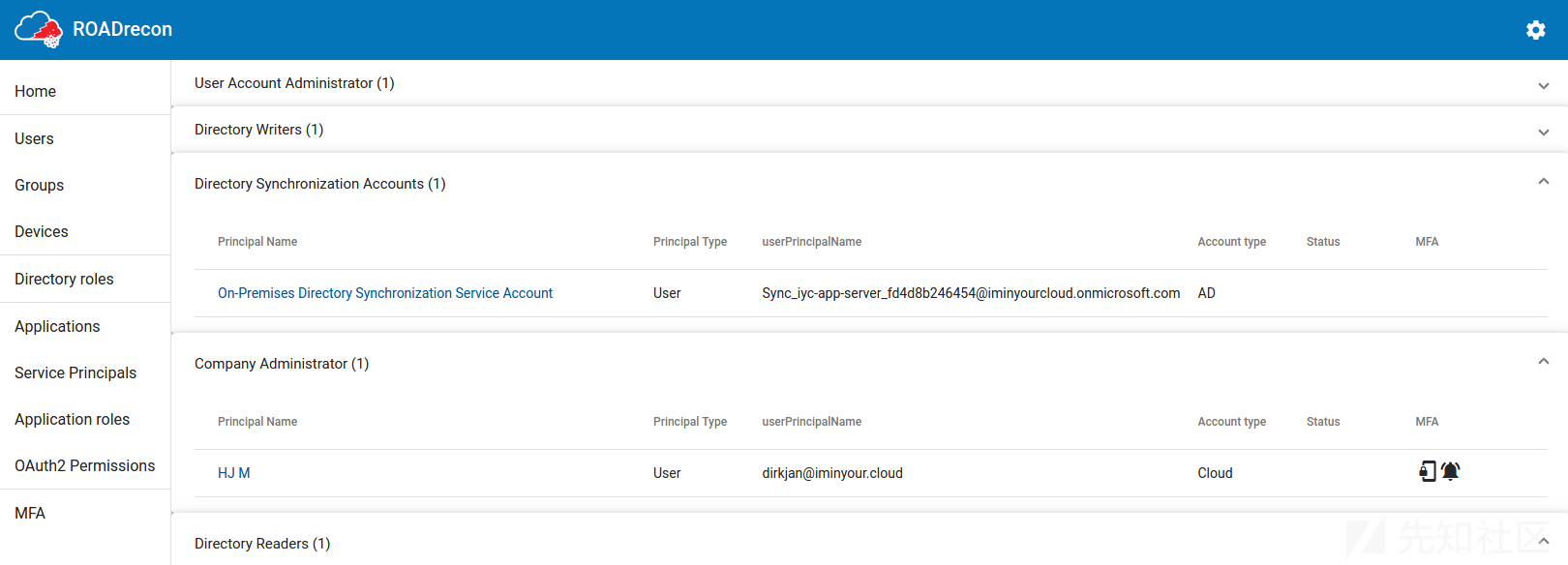
我最喜欢的一个视图是Directory Roles视图,因为该视图提供了一个非常快速的概览,了解哪些用户或服务帐户分配了特权角色。如果你使用一个有特权的帐户(蓝队)进行收集了MFA信息,你可以立即看到哪些帐户注册了MFA方法,哪些没有。
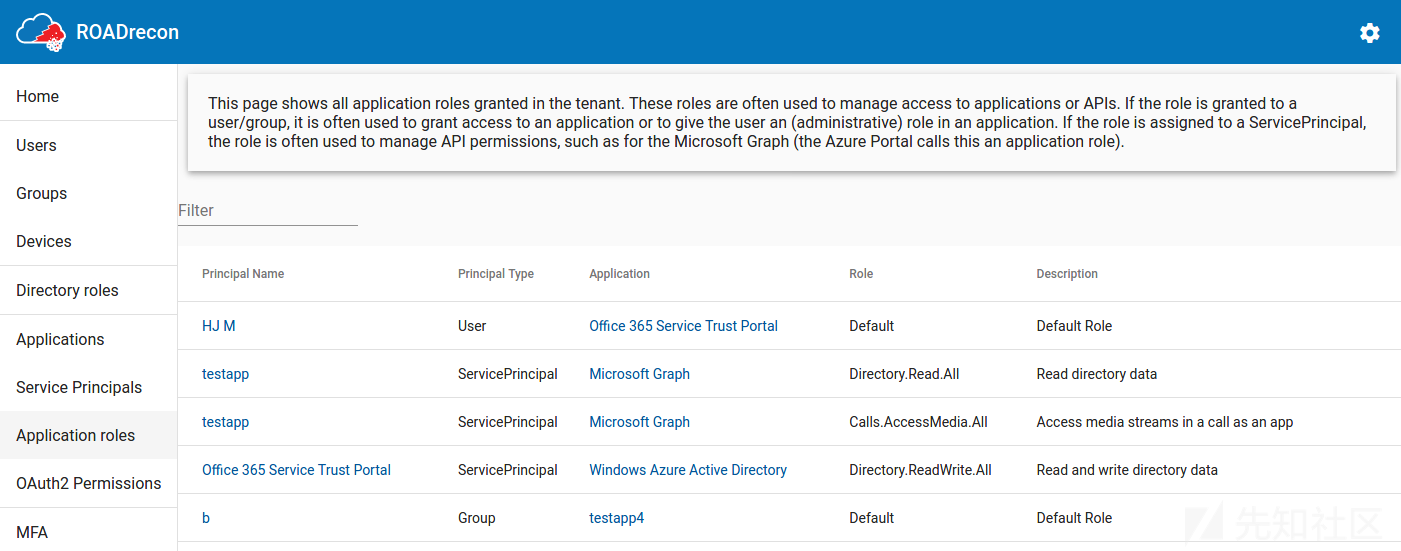
另一个是Application Roles页面,它显示了服务主体在Microsoft图中拥有的所有特权,以及在应用程序中为某个角色分配了哪些用户/组。
在GUI中还有一些东西还在开发中,我计划稍后添加更高级的过滤功能,但基本的东西已经在那里了,总的来说,它相当快,除非在大型环境中加载一些时间,。
ROADrecon插件 - 解析条件访问策略
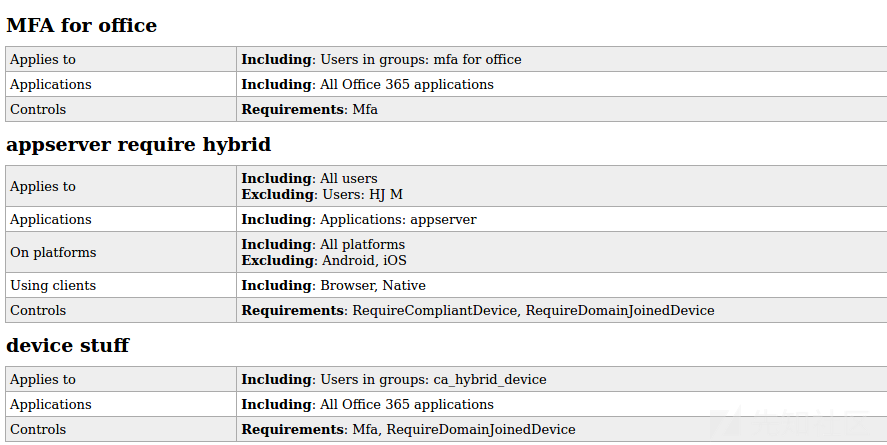
我已经提到了插件,其目标是让其他人更容易编写自己的插件或与ROADrecon交互的工具。我与同事Adrien Raulot一起开发的示例插件是条件访问策略插件,该插件尚未进入GUI。正如我在BlueHat演讲中所讨论的,在Azure Portal中,条件访问策略对于普通用户是不可见的。内部的Azure AD API允许任何人列出它们,但是它们的原始格式充满了guid,需要手动解决。ROADtools的“policy”插件将它们解析为可读格式并输出到一个静态HTML页面。由于在Azure AD中探索条件访问策略是一件很痛苦的事情,而且需要太多的点击,所以这个页面是我最喜欢的探索它们的方法之一。从红队的角度来看,条件访问策略是决定哪些应用程序具有更严格的访问控制(如需要MFA或托管设备)的最有价值的资源。
BloodHound
另一个很有潜力的插件是BloodHound插件。这个插件在数据库中读取Azure AD的对象,并将其写入包含BloodHound数据的(本地)neo4j数据库中。在使用BloodHound界面的自定义fork时,您可以可视化地探索用户、组和角色,包括与预置 Active Directory用户的链接(如果是同步环境的话)。
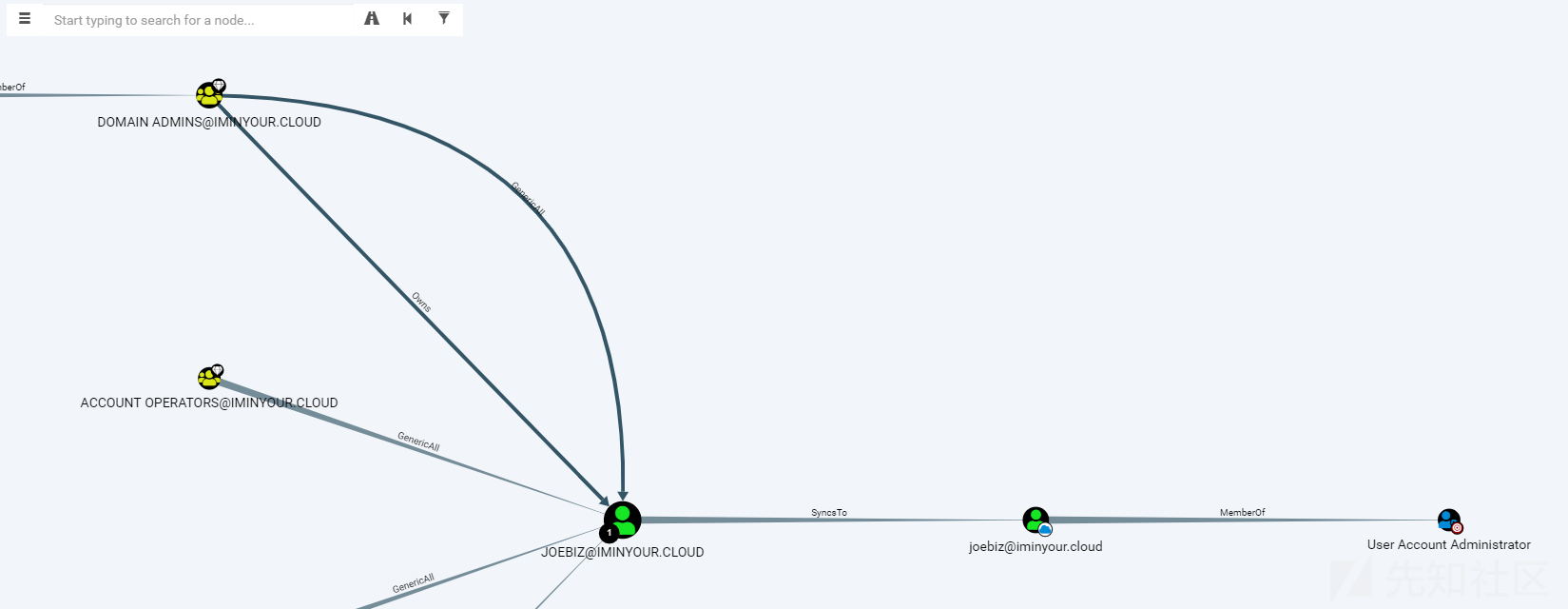

BloodHound仍在alpha版本,需要一些密码学知识才能真正得到所有的信息。我知道其他人(比如Harmj0y和tifkin_)也在编写一个支持Azure AD的BloodHound,所以我希望它能被进一步开发,甚至可能合并到官方的BloodHound项目中。
获取这些工具
最简单的安装方法是使用PyPi,在Azure Pipelines中可以使用来自Git的自动构建。
BloodHound的fork可以在https://github.com/dirkjanm/BloodHound-AzureAD上下载。
我也有很多带有ROADtools标志的贴纸(感谢Sanne的设计帮助!),一旦我们可以安全地再次召开会议,我就会分发出去!
防御
在我看来,枚举不是蓝队应重点关注的进攻技术。 防止未经授权的用户访问此信息的最佳方法是,通过严格的条件访问策略来管理允许用户从何处以及从何处使用其Azure AD凭据。 话虽这么说,已弃用的MSOnlinePowerShell模块中有一个设置可以防止使用Azure AD图进行枚举,此文档在此处记录。 我个人没有考虑绕过此功能,也没有考虑如果启用了此功能,Azure中的其他功能是否会中断。